Linkedin profilom adatainak elemzése
Ebben a riportban a saját Linkedin profilom adatait elemeztem
Az adatokat bárki le tudja tölteni. Ehhez a Linkedin-em a felső menüsoron a Me\Settings&Privacy menüpontra kell kattintani, majd utána a bal oldalon a Data Privacy-ra. Ott a Get a copy of your data-t kell kiválasztani. Ekkor megjelenik az Export your data rész, és ott ki lehet választani, hogy letöltsük az adatokat (Download larger data archive, including connections, verifications, contacts, account history, and information we infer about you based on your profile and activity). Itt a kérésnél először egy alapadatokat tartalmazó fájlokat kapunk e-mailben és kell kb. 24 órát várni, hogy megkapjuk e-mailben a teljes adatkészletet. Az adatokat Excel/csv formában jönnek le, amiket egyesével betöltve a Power Query-ben kellett még átalakítani. Én összesen 7 fájlt töltöttem be.
Először a Connection nevű fájlt, ami a Linkedin kapcsolataimat tartalmazza. Betöltve 1 oszlop látszik, minden adat egyben (a név, az e-mail cím, a vállalat, pozició, mikor csatlakozott). Ezeket szét kell szedni. A felső menüből Split Column by Delimeter-re kattintva lehet beállítani, hogy mi alapján bontsa szét, itt a vessző alapján (comma). Ezt végrehajtva szépen szét is bontja az oszlopokat. Itt azonban látszik, hogy van 3 felesleges sor az elején, ezt a Removed Top Rows-al el lehet távolítani. Ezután még látszik, hogy az oszlopoknak nincs neve, de ott van az első sorban, hogy pl. First Name, Last Name. Ezt, hogy megoldjuk a Use First Row as Headers használjuk. Még az adattípusokat ellenőrizve az látszik, hogy a csatlakozás dátuma nem dátum típus, így még át kell váltani (jobb egér gomb és Change Type). Én még az URL és az EmailAdress oszlopokat eltávolítottam, mert arra nem lesz szükségem. Így már ezt a fájlt be lehet tölteni a Power BI-ba (később még vissza kellett térni hozzá).
A többi fájlt nem részletezem egyesével, csak azokat az adattisztitási, transzformálási műveleteket összegzem, amiket el kellett végezni, hogy az adatmodellbe betölthető legyen.
Szinte mindenhol kellett a Split Column műveletet végrehajtani, sok helyen a dátum egybefüggősége miatt. Egyik helyen úgy hozta az adatokat, hogy a dátumnál nem nap/hónap/év sorrend volt, hanem hónap/nap/év. Így itt végül egyszerűen megcseréltem a szétszedett oszlopokat és utána újra összeraktam (Merged Columns). Ez egyébként az Invitations fájlnál volt.
Létrehoztam egy külön dátum táblát (Calendar), ahol több oszlopot adtam hozzá (év, hónap, hónap száma, hét száma stb). Ezt a táblát kapcsoltam hozzá a többi 7 tábla Dátum oszlopaival a Model View-nál. A kapcsolat egy a többhöz a Calendar táblából.
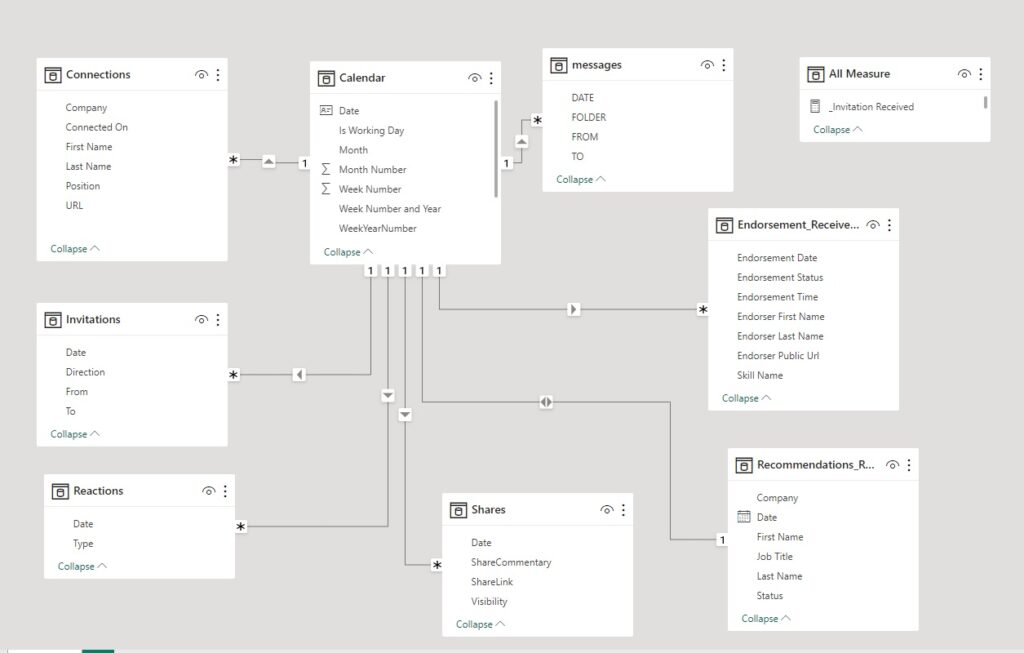
Az adatok megjelenítéséhez különböző számításokat végeztem, amiket egy külön táblába (All Measure) mentettem.
A Connections, a Reactions, a Shares, a Recommendation adatoknál a Count függvényt használtam. Ahhoz, hogy megszámoljam, hogy hány különböző cég (Company) van, a Distinctcount függvényt alkalmaztam. Az Endorsement adatoknál azt számoltam meg, hogy ki az aki „elfogadta”, vagyis a Status oszlopban „Accepted” szerepel. Ehhez a Calculate és egyik paramétereként a Count függvényt használtam. A Messages Sent adatoknál szintén Calculate és CountA függvény, a Messages Received adatoknál szintén és itt még a NOT és az IN operátort használtam.
A riport designjához a Power BI-ban hoztam létre a szövegdobozokat (Textbox), amibe a szövegeket írtam, valamint a Shapes menüből szúrtam be a Rectangles formákat és Basic Shapes-ből alakítottam ki a kört pl. a fotóm beszúrásához.
A főbb adatokat Card-okra tettem, mint a Connections, Reactions stb.
Egy Area Chart-ban ábrázoltam a Kapcsolatokat az idő függvényében, hónapok szerint rendezve. Itt problémába ütközhetsz, hogy nem időrendi sorrendbe rakja a hónapokat, hanem abc sorrendbe. Ehhez a Table View-re kell menni és a Calender táblát választani. Itt a Month oszlopra kattintunk és a Modelling fülre. A Sort by Colum megjelenik és ha lenyitjuk akkor lehet választani, hogy mi alapján. Ha a Month-ot választjuk akkor abc sorrendbe rakja, mert szöveges adatként érzékeli. Viszont van egy MonthNumber nevű oszlop, ami számokat tartalmaz és az 1-hez a január. 2-höz a február tartozik és így tovább. A Month oszlopon állva így MonthNumber szerint rendezzük a Sort by Column-nál. Amint ezt beállítjuk és visszamegyünk a riport nézetre, már látszik is az eredmény, hogy időrendbi sorrendbe rakja a hónapokat.
Clustered Column Chartban mutattam meg a Top 5 Companyt. Ezt úgy lehet elérni, hogy a Filters résznél, a Filters on this visual, és itt jelent esetben a Company-nál, a Filter type-t Top N-re állítva és Show items nál Top 5, majd a By Value-nál az értéket behúzva (ami itt a Total Connection measure). Itt egyébként az adatokból azt lehet megállapítani, hogy a legtöbben az OTP-től vannak ismerőseim itt, a második viszont azok, akik nem adtak meg céget, ez üres (blank) volt. Itt egyébként a Power Queryben „kicseréltem” az adatokat (Replaced Values), így látszik, hogy hányan nem adták meg a céget, ahol dolgoznak. (azt itt nem vizsgáltam, hogy esetleg valaki esetleg nem dolgozik).
A pozíciókra 2 vizualizációt készítettem. Az egyik egy Clustered bar chart, a top 3 pozícióval, a Total Connection arányában, vagyis, hogy a kapcsolatok között, melyik pozícióból volt a legtöbb. Itt is volt aki nem adta meg, hogy milyen pozícióban, munkakörben dolgozik, és ez a legtöbb.
A másik egy WordClud vizualizáció. Itt szövegesen jellenek meg a pozíciók, és az ami a legtöbb, az a legnagyobb betűvel.
Az üzeneteket egy Donut Charton ábrázoltam, így látszik, hogy mennyi volt bejövő és a kimenő üzenetek aránya.
Az Invitation szintén egy ilyen Donut Charton jelenítettem meg, viszont itt mivel „ki lettek kapcsolva” a szűrők (FILTER(ALL), így itt nincs hatással az, ha az időre (a hónapos charton) és/vagy a bármi másra kattintunk.
Természetesen több adatot is be lehet később vonni, több mindent is megjeleníteni, attól függ, hogy mi érdekel a Linkedin profilból.
FRISSITÉS: Időnként érdemes frissíteni az adatok, mert több kapcsolatunk lesz, több like-t kapunk stb. Ehhez újra le kell kérni az adatokat a Linkedin-től, letölteni a csv fájlokat, megvárni míg a teljes adatkészletet megkapjuk. Érdemes abba a mappába átmásolni, ahol az előzőek voltak. Innen nem lesz más teendő a riport frissítéséhez mint az adatforrást megváltoztatni. Ehhez a Transform Data-nál a legördülő menüre kell kattintani és ott a Data source settings-t választani. Itt látni fogod a riportban jelenleg használt összes adatforrás listáját. Válaszd ki a módosítani kivánt fájlt pl. itt a Connections-t és a Change source-nál tallózd ki az új fájlt. Kattints az Ok gombra, majd bezárás. Felül majd ott lesz, hogy „Apply changes” arra nyomj rá és kész is frissültek az adatok. Ezután publikáld újra, itt le tudod cserélni a meglévőt és teljesen automatikusan frissül, itt a beágyazott riport is frissült egyből.